
OpenAIは6月27日、ChatGPTなどの大規模言語モデル(LLM)の出力の誤りを検出するためのGPT-4ベースのモデル「CriticGPT」を発表しました。
CriticGPTは、人間によるAIトレーニングの際に、ChatGPTの回答の誤りを指摘することで、トレーニングの精度向上を支援します。
ChatGPTは、RLHF(人間からのフィードバックによる強化学習)と呼ばれる手法を用いて、人間との対話に適したモデルへと調整されています。RLHFでは、人間のAIトレーナーがChatGPTの異なる回答を比較評価し、その結果を学習にフィードバックします。
しかし、モデルの推論能力や挙動が高度化するにつれ、ChatGPTの誤りはより微妙化し、AIトレーナーにとって誤りを発見することが困難になっています。これはRLHFの根本的な限界であり、モデルが人間の能力を超えていくにつれて、モデルの調整はますます困難になる可能性があります。
CriticGPTはこの課題に対処するために開発されました。CriticGPTは、ChatGPTの回答の不正確な点を指摘する批評文を作成します。
CriticGPTもChatGPTと同様にRLHFを用いてトレーニングされていますが、ChatGPTとは異なり、誤りを含む大量の入力を学習データとして使用し、それらの誤りを批評するように訓練されています。
具体的には、AIトレーナーがChatGPTによって書かれたコードに手動で誤りを挿入し、その誤りを発見した場合にどのようなフィードバックを行うかを記述した例を作成。次に同じトレーナーが、修正されたコードに対する複数の批評文を比較し、どの批評文が挿入された誤りを正しく指摘しているかを評価します。

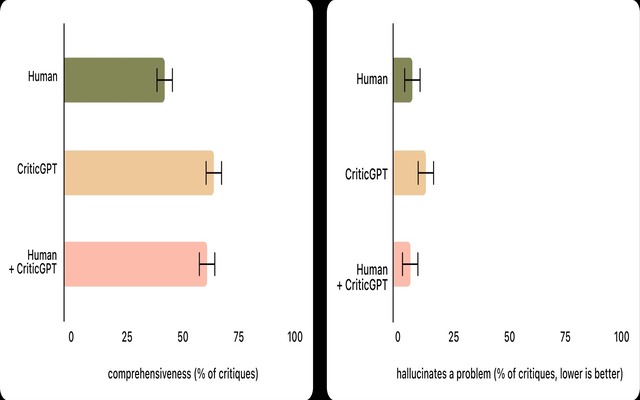
OpenAIによると、CriticGPTの提案は必ずしも常に正しいわけではないが、AIトレーナーがモデルの回答の誤りを発見するのを大きく支援することが分かっています。
CriticGPTの支援を受けてコードレビューを行った場合、支援なしの場合と比較して、約60%の確率でパフォーマンスが向上しました。
また、CriticGPTを用いることで、AIトレーナーはより包括的な批評文を作成することができ、モデル単独で批評文を作成する場合よりも誤った指摘を減らすことができたといいます。
現時点ではChatGPTの比較的短い回答を対象にトレーニングされています。OpenAIは、より長文で複雑なタスクを評価できるようにするために、CriticGPTの改良が必要だとしています。